Открыл для себя очередную группу - Blackfoot Sue. Напоминают, временами, горячо любимых Slade.
Лучшее из того, что я слушал за последнее время.
среда, 27 февраля 2013 г.
ДДУ, 214 ФЗ и прочая непонятная хрень
В начале ноября заключили договор уступки на покупку квартиры по договору долевого участия в строительстве, зарегистрировали в юстиции, посмотрели сроки сдачи 14.01.2013-15.02.2013 и были рады.
16.01.2013 позвонил я застройщику и спросил когда уже ключи будут выдавать. А застройщик мне молвит человеческим голосом - а мы из-за декабрьских морозов (видимо, изначально планировалось в Сочи этот дом строить и особенности температурного режима Сибирского Федерального Округа учтены не были) сроки переносим, давайте заключать дополнительное соглашение к договору о переносе сроков. Я у них спрашиваю - а насколько вы сроки переносите? Они отвечают уклончиво, мол, разрешение на строительство у нас выдано сроком до 31.03.2013, вот к этому времени сдать и должны. Я им сказал, что подумаю.
И подумал я вот что - если они мне сами позвонят и предложат подписать доп. соглашение, то я, пожалуй, не буду выпендриваться - всё-таки к тому что сроки сорвут я был готов. Но они звонить всё не решались и подумал я, что пусть так всё и остаётся. Однако, недавно, где-то 20.02.2013, звонят мне родители и говорят, что на моё имя пришло заказное письмо. Поскольку адрес, при заключении договора, я указывал по прописке (ибо хрен его знает где мы завтра жить будем, а у родителей вроде как стабильность), то подумал, что письмо от застройщика. И вот вчера, 26.02.2013, выяснилось, что был прав.
Получил письмо, а там русским по белому написано, что были произведены замеры квартиры и квартира моя оказалась на 0,7 квадратных метра больше, чем в договоре указано. Т.е. застройщик от меня денюжек на 28,5 тысяч рублей меньше получил, чем хотелось бы. И пишут они, что в течение 20 дней эти деньги они очень бы хотели получить.
А сегодня звонят мне и наивным женским голосом спрашивают когда я буду так добр, что соизволю явиться и подписать доп. соглашение о переносе сроков. Т.е. с меня они деньги хотят в полном объёме получить, а вот за срыв сроков строительства они мне неустойку платить не хотят. В общем, будем смотреть что можно сделать. Вечером надо будет изучить договоры (вчера, увы, не успел) и 214 ФЗ "Об участии в долевом строительстве...", благополучно мной распечатанный.
upd
Сел вечером за изучение ДДУ и договора уступки. В моём ДДУ прописано, что в случае отличия реальной площади от проектной, разница выплачивается либо застройщиком, либо участником долевого строительства, т.е. как и в 214 ФЗ. В интернетах пишут, что обычно добавляется пункт, что такие выплаты не производятся, если реальная площадь отличается меньше чем на 1% от проектной, но у меня этого нет, значит будем платить.
Теперь если дом сдадут не раньше 30.03.2013 - сумма неустойки, которую должен выплатить застройщик за срыв сроков, как раз будет примерно равна сумме которую я им уплачу за доп. площадь. Будем посмотреть.
16.01.2013 позвонил я застройщику и спросил когда уже ключи будут выдавать. А застройщик мне молвит человеческим голосом - а мы из-за декабрьских морозов (видимо, изначально планировалось в Сочи этот дом строить и особенности температурного режима Сибирского Федерального Округа учтены не были) сроки переносим, давайте заключать дополнительное соглашение к договору о переносе сроков. Я у них спрашиваю - а насколько вы сроки переносите? Они отвечают уклончиво, мол, разрешение на строительство у нас выдано сроком до 31.03.2013, вот к этому времени сдать и должны. Я им сказал, что подумаю.
И подумал я вот что - если они мне сами позвонят и предложат подписать доп. соглашение, то я, пожалуй, не буду выпендриваться - всё-таки к тому что сроки сорвут я был готов. Но они звонить всё не решались и подумал я, что пусть так всё и остаётся. Однако, недавно, где-то 20.02.2013, звонят мне родители и говорят, что на моё имя пришло заказное письмо. Поскольку адрес, при заключении договора, я указывал по прописке (ибо хрен его знает где мы завтра жить будем, а у родителей вроде как стабильность), то подумал, что письмо от застройщика. И вот вчера, 26.02.2013, выяснилось, что был прав.
Получил письмо, а там русским по белому написано, что были произведены замеры квартиры и квартира моя оказалась на 0,7 квадратных метра больше, чем в договоре указано. Т.е. застройщик от меня денюжек на 28,5 тысяч рублей меньше получил, чем хотелось бы. И пишут они, что в течение 20 дней эти деньги они очень бы хотели получить.
А сегодня звонят мне и наивным женским голосом спрашивают когда я буду так добр, что соизволю явиться и подписать доп. соглашение о переносе сроков. Т.е. с меня они деньги хотят в полном объёме получить, а вот за срыв сроков строительства они мне неустойку платить не хотят. В общем, будем смотреть что можно сделать. Вечером надо будет изучить договоры (вчера, увы, не успел) и 214 ФЗ "Об участии в долевом строительстве...", благополучно мной распечатанный.
upd
Сел вечером за изучение ДДУ и договора уступки. В моём ДДУ прописано, что в случае отличия реальной площади от проектной, разница выплачивается либо застройщиком, либо участником долевого строительства, т.е. как и в 214 ФЗ. В интернетах пишут, что обычно добавляется пункт, что такие выплаты не производятся, если реальная площадь отличается меньше чем на 1% от проектной, но у меня этого нет, значит будем платить.
Теперь если дом сдадут не раньше 30.03.2013 - сумма неустойки, которую должен выплатить застройщик за срыв сроков, как раз будет примерно равна сумме которую я им уплачу за доп. площадь. Будем посмотреть.
вторник, 26 февраля 2013 г.
24 Hours of PASS. Russian Edition
21-го марта 2013-го года состоится вторая онлайн-конференция "24 Hours of PASS". Необычность этой конференции заключается в том, что она идёт 24 часа (в идеале, у нас 23 часа). Начинается 21-го марта в 00:00 и заканчивается 21-го марта в 23:00. Всего предполагается 23 часовых доклада.
Зарегистрироваться и ознакомиться с программой можно здесь (там же есть ссылки на записи с прошлогодней конференции).
Зарегистрироваться и ознакомиться с программой можно здесь (там же есть ссылки на записи с прошлогодней конференции).
понедельник, 25 февраля 2013 г.
Денис Попов 2.0
Я просто оставлю это здесь.
http://habrahabr.ru/post/170487/
http://sporaw.livejournal.com/153328.html
http://www.anti-malware.ru/forum/index.php?showtopic=25141
http://www.linux.org.ru/forum/talks/8885213/
http://andrewkochetkov.livejournal.com/13569.html
Интересно, в этот раз на ноуты будут предустанавливать антивирус Бабушкина?
http://habrahabr.ru/post/170487/
http://sporaw.livejournal.com/153328.html
http://www.anti-malware.ru/forum/index.php?showtopic=25141
http://www.linux.org.ru/forum/talks/8885213/
http://andrewkochetkov.livejournal.com/13569.html
Интересно, в этот раз на ноуты будут предустанавливать антивирус Бабушкина?
пятница, 22 февраля 2013 г.
Подборка постов по SQL Server за неделю
Подумал, что надо как-то сохранять ссылки на те посты по SQL Server которые меня заинтересовали. Я их, конечно, и так сохранял - отмечал в rss-ридере, но, думаю, так будет удобнее. Плюс, возможно, такая подборка будет интересна кому-то кроме меня. Постараюсь делать такую подборку каждую пятницу (если будет из чего).
1. DBCC WRITEPAGE: an introduction - пост в блоге Paul Randal, о котором я уже написал раньше, поскольку такая возможность действительно меня очень удивила.
2. Corruption demo databases and scripts - пост всё того же Paul Randal который я по непонятным причинам пропустил и наткнулся на него совершенно случайно. По ссылке можно найти как готовые БД, так и скрипты для их создания. Особенность этих БД заключается в том, что все они содержат в себе "повреждения" и их можно использовать для каких либо демонстраций, либо для тренировки.
3. SQL Server statistics questions we were too shy to ask - Grant Fritchey отвечает на множество вопросов, связанных со статистикой в SQL Server
4. SQL Server 2008 Statistics: What does a DBA need to know? - так же посвящён статистике. Matt Bowler рассказывает о том, что с его точки зрения, о статистике должен знать каждый DBA.
5. Troubleshooting and fixing SQL Server page level corruption - Derek Colley объясняет как разобраться с ошибкой "SQL Server detected a logical consistency-based I/O error".
6. 7 Things Developers Should Know About SQL Server - Brent Ozar, бывший разработчик, MCM, администратор баз данных и консультант рассказывает о том, что начинающие разработчики должны учитывать при работе с SQL Server. Перевод этого поста я сделал на хабре.
7. T-SQL script to keep CPU busy - Pinal Dave приводит пример скрипта, позволяющего загрузить CPU на 100% в течение 30-60 секунд.
1. DBCC WRITEPAGE: an introduction - пост в блоге Paul Randal, о котором я уже написал раньше, поскольку такая возможность действительно меня очень удивила.
2. Corruption demo databases and scripts - пост всё того же Paul Randal который я по непонятным причинам пропустил и наткнулся на него совершенно случайно. По ссылке можно найти как готовые БД, так и скрипты для их создания. Особенность этих БД заключается в том, что все они содержат в себе "повреждения" и их можно использовать для каких либо демонстраций, либо для тренировки.
3. SQL Server statistics questions we were too shy to ask - Grant Fritchey отвечает на множество вопросов, связанных со статистикой в SQL Server
4. SQL Server 2008 Statistics: What does a DBA need to know? - так же посвящён статистике. Matt Bowler рассказывает о том, что с его точки зрения, о статистике должен знать каждый DBA.
5. Troubleshooting and fixing SQL Server page level corruption - Derek Colley объясняет как разобраться с ошибкой "SQL Server detected a logical consistency-based I/O error".
6. 7 Things Developers Should Know About SQL Server - Brent Ozar, бывший разработчик, MCM, администратор баз данных и консультант рассказывает о том, что начинающие разработчики должны учитывать при работе с SQL Server. Перевод этого поста я сделал на хабре.
7. T-SQL script to keep CPU busy - Pinal Dave приводит пример скрипта, позволяющего загрузить CPU на 100% в течение 30-60 секунд.
среда, 20 февраля 2013 г.
О пользе первоисточников
Увидел у Вячеслава Гилёва в G+ ссылку на его блог, где он наглядно демонстрирует преимущество "железных" машин над виртуальными. Вот так это выглядело:
 На картинках отлично видно, что "железная" машина в два с лишним раза уделывает виртуалку по производительности. Успех, вроде как. Но, вот по ссылке на первоисточник, всё совершенно не так:
На картинках отлично видно, что "железная" машина в два с лишним раза уделывает виртуалку по производительности. Успех, вроде как. Но, вот по ссылке на первоисточник, всё совершенно не так:


Ситуация, конечно, странная, но использовать результаты опыта "наоборот" - это как-то не очень правильно.
upd
На инфостарте нашлось объяснение таким результатам - энергосбережение процессора (к вопросу о вреде этой штуки на серверах, кстати). Теперь результаты как в блоге Гилёва, так и на инфостарте выглядят так:
 Виртуалка, как и ожидалось, показывает меньше попугаев, но не в 2 с лишним раза, а практически столько же. Отставание от физической машины незначительное.
Виртуалка, как и ожидалось, показывает меньше попугаев, но не в 2 с лишним раза, а практически столько же. Отставание от физической машины незначительное.
Как пишет Вячеслав в своём блоге: "Выводы делайте сами...". :)


Т.е. у человека, проводившего "исследование", виртуалка уделала живую машину, а не наоборот, как говорит об этом Вячеслав.
Ну и ещё один скрин комментов с инфостарта, где автор исследования говорит, что он не ошибся и у него виртуалка действительно работает быстрее (точнее говоря, не виртуалка работает быстрее, а тест показывает больше "попугаев"):
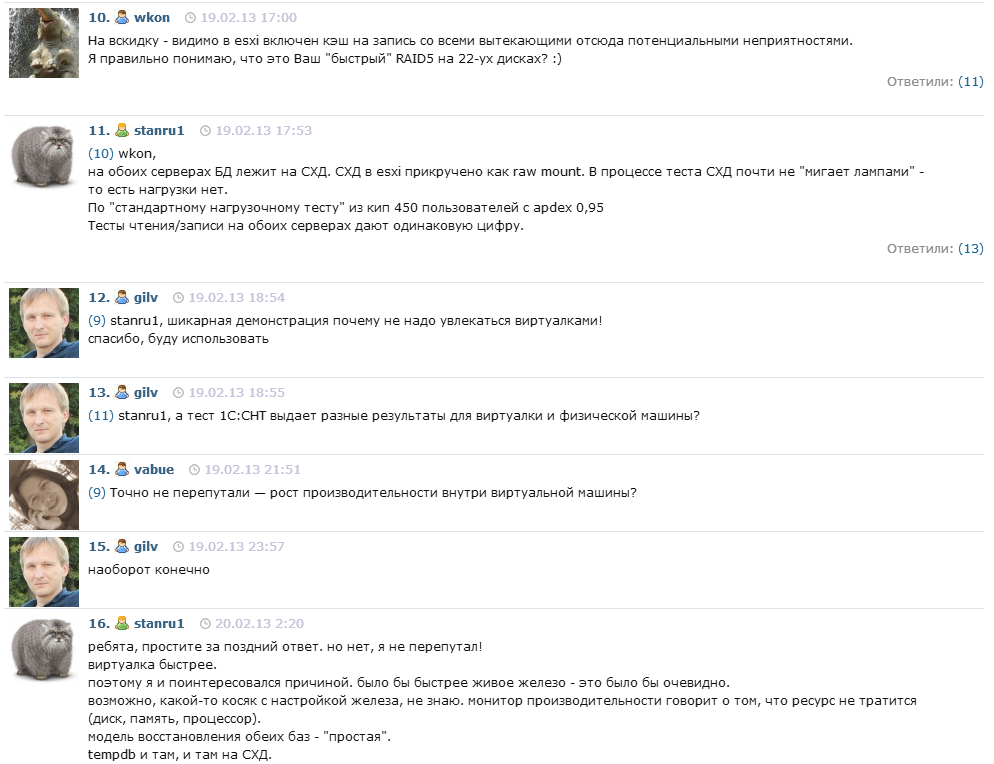
upd
На инфостарте нашлось объяснение таким результатам - энергосбережение процессора (к вопросу о вреде этой штуки на серверах, кстати). Теперь результаты как в блоге Гилёва, так и на инфостарте выглядят так:

Как пишет Вячеслав в своём блоге: "Выводы делайте сами...". :)
понедельник, 18 февраля 2013 г.
SQL Server. DBCC WRITEPAGE. Ещё одна недокументированная функция
Закончив с учёбой и появивишись на работе, добрался до гугл ридера. Там меня ждал вот такой вот пост Пола Рэндала, посвящённый недокументированной DBCC WRITEPAGE (какой-то месяц недокументированных команд SQL Server прям).
Название, в принципе, вполне себе говорящее. Она позволяет "на лету" подправить содержимое ЛЮБОЙ страницы в БД.
Пол говорит, что эта штука может использоваться коммандой SQL Team для починки БД клиента. Плюс с её помощью можно испортить себе БД для тестов, либо наоборот на лету починить повреждённую БД (в том случае если есть полная уверенность в своих действиях).
Синтатксис у неё простой:
dbcc WRITEPAGE ({'dbname' | dbid}, fileid, pageid, offset, length, data [, directORbufferpool])
(
проверить, что синтаксис не отличается от приведённого выше, можно очень просто:
DBCC TRACEON (2588);
GO
DBCC HELP ('WRITEPAGE');
GO
)
, где offset - смещение в байтах относительно начала файла (начало файла = 0), length - длина изменения в байтах (от 1 до 8), data - новые данные для вставки (в 16-м виде, '0xAABBCC' - пример строки длиной три байта), directORbufferpool - должен ли быть задействован buffer pool (да - 0, нет - 1).
Последний параметр очень важен. Если вы укажете, что buffer pool задействовать не нужно, то запись будет произведена непосредственно на диск! Это значит, что SQL Server не пересчитает контрольную сумму, и при попытке чтения изменённой страницы, появится сообщение о повреждении страницы.
Пример такого повреждения можно посмотреть непосредственно в блоге Пола Рэндала, ссылка есть в начале моего поста.
Конечно, такой функционал не должен применяться на рабочем сервере, только на тестовом и в тестовых целях. DBCC WRITEPAGE может стать ещё одним способом выстрелить себе в ногу, при попытке использовать его на рабочей базе, не до конца осознавая собственные действия.
Название, в принципе, вполне себе говорящее. Она позволяет "на лету" подправить содержимое ЛЮБОЙ страницы в БД.
Пол говорит, что эта штука может использоваться коммандой SQL Team для починки БД клиента. Плюс с её помощью можно испортить себе БД для тестов, либо наоборот на лету починить повреждённую БД (в том случае если есть полная уверенность в своих действиях).
Синтатксис у неё простой:
dbcc WRITEPAGE ({'dbname' | dbid}, fileid, pageid, offset, length, data [, directORbufferpool])
(
проверить, что синтаксис не отличается от приведённого выше, можно очень просто:
DBCC TRACEON (2588);
GO
DBCC HELP ('WRITEPAGE');
GO
)
, где offset - смещение в байтах относительно начала файла (начало файла = 0), length - длина изменения в байтах (от 1 до 8), data - новые данные для вставки (в 16-м виде, '0xAABBCC' - пример строки длиной три байта), directORbufferpool - должен ли быть задействован buffer pool (да - 0, нет - 1).
Последний параметр очень важен. Если вы укажете, что buffer pool задействовать не нужно, то запись будет произведена непосредственно на диск! Это значит, что SQL Server не пересчитает контрольную сумму, и при попытке чтения изменённой страницы, появится сообщение о повреждении страницы.
Пример такого повреждения можно посмотреть непосредственно в блоге Пола Рэндала, ссылка есть в начале моего поста.
Конечно, такой функционал не должен применяться на рабочем сервере, только на тестовом и в тестовых целях. DBCC WRITEPAGE может стать ещё одним способом выстрелить себе в ногу, при попытке использовать его на рабочей базе, не до конца осознавая собственные действия.
воскресенье, 17 февраля 2013 г.
Обучение в Softline. Итоги.
Курс закончен, сертификат получен. Попытаюсь разобраться, что этот курс мне дал.
Собственно, не так уж много. Первое - я потыкался с SecretNet'ом. Второе, узнал немного о проведении проверок и получил вполне очевидные рекомендации. Третье - узнал о WingDoc. Если мы будем защищаться целиком своими силами - он может быть полезен. Четвёртое - немного узнал о Microsoft NAP. Вот его мы, возможно, когда-нибудь используем. Пятое - методика расчёта риска от Digital Security, с ней нужно разбираться, но первое впечатление таково, что это может быть полезным при работе. Ну и последнее - некоторое представление об ITIL и PMBok, хотя, про них нужно почитать самостоятельно, чтобы понять будет ли мне это полезно хоть когда-нибудь (словам лектора верить очень сложно, после того как он расшифровал ITSM как IT Security Management и два часа рассказывало том, что этот раздел посвящён исключительно ИБ).
В общем, после курсов у меня появилась "пища для размышлений", но шесть дней на это всё - это перебор. Курс можно было бы упихнуть в пару дней, либо в пяток вебинаров - было бы дешевле и без такого значительного отрыва от производства.
пятница, 15 февраля 2013 г.
День пятый. Ватный.
Учитывая, что вчера мы закончили практически всё, сегодняшний день был чрезвычайно ватным. Единственное более-менее интересное, что было сегодня - это ссылка на http://csrc.nist.gov - кучу американскх рекомендаций по ИБ, первые из которых относятся аж к 1995-му году, а последние к декабрю 2012-го.
В конце дня потыкались в WingDoc, о котором уже было упоминание несколько дней назад. Запросили демо-версию и обнаружили, что эта демка умеет делать только акты классификации ИСПДн, т.е. на модель угроз посмотреть не получилось. Плюс, выяснилось, что даже акт классификации она нам не сформирует, поскольку на машине не установлен Word, без которого документы не формируются.
В общем, в очередной раз я убедился в том, что русские поделки для ЗИ, с сертификатами ФСТЭК, создаются не для улучшения защиты, а исключительно для выкачивания денег.
четверг, 14 февраля 2013 г.
Четвёртый день
Главное моё открытие сегодняшнего дня - ИП - это не юридическое лицо, соответственно, его ИНН, адрес, телефон и т.д. - это ПДн. Я почему-то был уверен, что ИП - это юридические лица. Нужно разобраться, ведь часть данных ИП делают общедоступными - на каждой торговой точке, по крайней мере, ИП-ик должен разместить свой ИНН. Возможно, с адресом та же история.
Поигрались ещё немного с SecretNet, с контролем целостности. Сегодня всё получилось нормально. Выбрали файлы для отслеживания и действие при нарушении целостности. Действия зависят от того как именно эта целостность контроллируется - либо с помощью хэш-функции, либо с помощью сравнения содержимого (т.е. SecretNet может в качестве эталона запомнить всё содержимое нужного файла). Если используется хэш-функция - SecretNet может либо проигнорировать это нарушение, либо заблокировать компьютер, либо заменить эталонное значение на изменённое. Т.е. при первом варианте, в журнале SecretNet'a появится запись о нарушении целостности, во втором тоже самое плюс заблокируется компьютер, в третьем - запись в журнале и замена эталонного значения. При этом, вернуться к эталону будет невозможно! Т.е. мы узнаем, что файл отличается от эталона, но что там был за эталон мы никогда не узнаем. Если же мы, например, будем проверять целостность операционной системы и вирус изменит содержимое какого-то файла, то, при неправильной настройке, "испорченный" файл может стать эталонным...
Для того, чтобы появилась возможность "вернуться" SecretNet в качестве эталона может использовать всё содержимое исходного файла. В этом случае, можно просто заменить контролируемый изменённый файл из сохранённого значения. То же самое произойдёт при удалении файла.
Спросил про то как правильно организовать "поздравлялку" с днями рождения. У нас используется программа birthday - она выводит "сегодняшних" и "завтрашних" юбиляров. Вопрос - какое основание использовать при сборе этих данных?
Предлагается два варианта - первый, в трудовой договор вписывать пункт о поздравлениях. В этом случае не нужно будет брать согласие, а в качестве основания обработки в перечне ПДн можно указать: "исполнение трудового договора". Хотя, конечно, вариант сомнительный.
Другой вариант - в какой-нибудь "кодекс корпоративной этики" добавить "поздравлялочный" пункт, а в согласии и перечне ссылаться на этот кодекс. Тут есть одно большое НО - когда я составлял перечень ПДн на заводе, находил информацию о том, что в качестве основания нельзя использовать локальные акты - только законы и НПА, либо Устав. Само-собой, в Устав никто ничего подобного вписывать не будет, поэтому, насколько законным будет вариант с локальным актом непонятно.
Видимо, будем искать третий вариант.
Немного узнал про Microsoft NAP. Должно быть удобная штука для тех организаций, в которые могут подключаться, например, домашние ноутбуки. Принцип примерно такой - в сети хранятся "эталонные" настройки - антивирусная программа, минимальный набор установленных обновлений, ОС, сетевые настройки и, при включении домашнего ноутбука в сеть, настройки ноута сверяются с эталонными. При совпадении ноутбук попадает в сеть, при несовпадении, настройки ноутбука "догоняются" до минимально необходимых и проверка повторяется.
Тоже стоит подумать о применимости. Может быть, если мы-таки доживём до подключения к сети из дома, эта штука и пригодится.
Ну и напоследок, нам дали рекомендации по тому как себя вести в случае проверки:
1. Сразу же после получения программы проверки - собрать всю документацию и, при возможности, дописать недостающее.
2. Оповестить всех сотрудников о предстоящей проверке. Заставить всех "освежить память", чтобы они помнили на основании каких инструкций они получают доступ к ПДн.
3. Документы должны содержать актуальную информацию на дату проверки.
4. Уделить особое внимание:
1) организации пропускного режима;
2) отделу кадров;
3) бухгалтерии;
4) содержимому сайта - тому что общедоступно, возможно, туда могли попасть ПДн не являющиеся общедоступными.
5. Оперативно реагировать на замечания проверяющих. Если исправлять небольшие недочёты по ходу првоерки, возможно, это устроит проверяющих и никаких предписаний выписано не будет.
Поигрались ещё немного с SecretNet, с контролем целостности. Сегодня всё получилось нормально. Выбрали файлы для отслеживания и действие при нарушении целостности. Действия зависят от того как именно эта целостность контроллируется - либо с помощью хэш-функции, либо с помощью сравнения содержимого (т.е. SecretNet может в качестве эталона запомнить всё содержимое нужного файла). Если используется хэш-функция - SecretNet может либо проигнорировать это нарушение, либо заблокировать компьютер, либо заменить эталонное значение на изменённое. Т.е. при первом варианте, в журнале SecretNet'a появится запись о нарушении целостности, во втором тоже самое плюс заблокируется компьютер, в третьем - запись в журнале и замена эталонного значения. При этом, вернуться к эталону будет невозможно! Т.е. мы узнаем, что файл отличается от эталона, но что там был за эталон мы никогда не узнаем. Если же мы, например, будем проверять целостность операционной системы и вирус изменит содержимое какого-то файла, то, при неправильной настройке, "испорченный" файл может стать эталонным...
Для того, чтобы появилась возможность "вернуться" SecretNet в качестве эталона может использовать всё содержимое исходного файла. В этом случае, можно просто заменить контролируемый изменённый файл из сохранённого значения. То же самое произойдёт при удалении файла.
Спросил про то как правильно организовать "поздравлялку" с днями рождения. У нас используется программа birthday - она выводит "сегодняшних" и "завтрашних" юбиляров. Вопрос - какое основание использовать при сборе этих данных?
Предлагается два варианта - первый, в трудовой договор вписывать пункт о поздравлениях. В этом случае не нужно будет брать согласие, а в качестве основания обработки в перечне ПДн можно указать: "исполнение трудового договора". Хотя, конечно, вариант сомнительный.
Другой вариант - в какой-нибудь "кодекс корпоративной этики" добавить "поздравлялочный" пункт, а в согласии и перечне ссылаться на этот кодекс. Тут есть одно большое НО - когда я составлял перечень ПДн на заводе, находил информацию о том, что в качестве основания нельзя использовать локальные акты - только законы и НПА, либо Устав. Само-собой, в Устав никто ничего подобного вписывать не будет, поэтому, насколько законным будет вариант с локальным актом непонятно.
Видимо, будем искать третий вариант.
Немного узнал про Microsoft NAP. Должно быть удобная штука для тех организаций, в которые могут подключаться, например, домашние ноутбуки. Принцип примерно такой - в сети хранятся "эталонные" настройки - антивирусная программа, минимальный набор установленных обновлений, ОС, сетевые настройки и, при включении домашнего ноутбука в сеть, настройки ноута сверяются с эталонными. При совпадении ноутбук попадает в сеть, при несовпадении, настройки ноутбука "догоняются" до минимально необходимых и проверка повторяется.
Тоже стоит подумать о применимости. Может быть, если мы-таки доживём до подключения к сети из дома, эта штука и пригодится.
Ну и напоследок, нам дали рекомендации по тому как себя вести в случае проверки:
1. Сразу же после получения программы проверки - собрать всю документацию и, при возможности, дописать недостающее.
2. Оповестить всех сотрудников о предстоящей проверке. Заставить всех "освежить память", чтобы они помнили на основании каких инструкций они получают доступ к ПДн.
3. Документы должны содержать актуальную информацию на дату проверки.
4. Уделить особое внимание:
1) организации пропускного режима;
2) отделу кадров;
3) бухгалтерии;
4) содержимому сайта - тому что общедоступно, возможно, туда могли попасть ПДн не являющиеся общедоступными.
5. Оперативно реагировать на замечания проверяющих. Если исправлять небольшие недочёты по ходу првоерки, возможно, это устроит проверяющих и никаких предписаний выписано не будет.
среда, 13 февраля 2013 г.
День третий. Экватор
Сегодняшний день начался с установки и настройки SecretNet'a. Он используется для контроля доступа к файлам, содержащим ПДн (в т.ч. печати); контроля целостности как файлов, содержащих ПДн, так и операционной системы; контроля устройств.
Контроль доступа осуществляется на основе мандатного или дискреционного механизмов. Дискреционный доступ реализован и в операционной системе (каждому конкретному файлу "назначаются" пользователи, которые могут читать/писать/изменять файл) и не особо интересен. С мандатным интереснее. Во-первых, выделяются категории файлов, например - ПДн, коммерческая тайна и общедоступные данные. Во-вторых, каждому файлу назначается выбранная категория (поддерживается механизм наследования, т.е. можно на папку повешать "гриф" ПДн и все файлы, созданные в ней, или перемещённые туда, будут обладать этим грифом). В-третьих, для каждого пользователя определяется "наиболее серьёзный" гриф, который должен быть ему доступен и имеет ли этот пользователь возможность самостоятельного назначения грифов для файлов. Т.е., если пользователю, например, доступен гриф ПДн, то он сможет видеть все общедоступные файлы и файлы с грифом "ПДн", "коммерческая тайна" будет ему недоступна, а пользователь с правами доступа к коммерческой тайне, будет иметь возможность доступа к данным с любым грифом.
Проблемных мест, к сожалению, хватает. Во-первых, имеется возможность назначения всего трёх видов грифов, один из которых должен быть общедоступным. Это достаточно крупное разделение. Во-вторых, назначение доступных грифов пользователям - оно производится для каждого пользователя, нельзя назначить доступность грифа группе пользователей.
Контроль устройств. С ним всё относительно просто. Выбираются устройства и назначаются разрешения для конкретных пользователей. Удобно тем, что можно каждому пользователю выдать по флэшке и разрешить компьютере втыкать этому пользователю именно эту флэшку, а все остальные накопители запретить. В плане учёта материальных носителей ПДн - очень удобно. Есть возможность назначать права вообще на всё - вплоть до ядер процессора - применимость не совсем понятна, но есть и ладно.
Контроль целостности. К сожалению, сегодня мы с ним разобраться не успели. Смогли выбрать каталог для контроля целостности, создать там пару файлов и задать эталонные значения. Что должно происходить дальше - непонятно - то ли SecretNet должен запретить их изменение, то ли не должен. Ответ получить не смогли. Единственное, что контроль целостности ОС тормозит так сильно, что загрузка ОС вместо привычных 3-4 минут тянулась минут 10. Если на заводе загрузка будет идти столько же - пользователи нас казнят.
Плюс, нам не показывали, но сказали, что есть "центральная административная" консоль, через которую SecretNet можно настраивать в сети удалённо, со своего рабочего места. На курсах в ОмГУ говорили, что при таком варианте все журналы сообщений будут по сети сливаться на центральную машину и генерировать приличный траффик, тут же говорят, что журналы будут храниться локально и их просто можно просматривать с "центральной" машины.
После SecretNet'a некоторое время потратили на модель угроз. Ничего нового не было, всё есть в базовой модели угроз ФСТЭК и их же методических рекомендациях по выявлению актуальных угроз. Единственное, что при определении уровня исходной защищённости ("УИЗ"), можно сыграть на нечёткости формулировок и снизить этот уровень (например под одноточечным доступом в сеть общего пользования можно понимать как отдельный компьютер, "физически подключенный" к интернету, так и шлюз, через который выходит в интернет сотня пользователей).
Кроме того, для составления модели угроз можно воспользоваться программным продуктом WingDoc, он стоит порядка 15 тыр, гуглится легко. Отвечая на вопросы программы, формируется модель угроз и какие-то сопутствующие документы.
До составления модели угроз самостоятельно я не доходил, так что для меня стало открытием, что для актуальных угроз (например, хищение hdd из системного блока без боковой крышки), нужно составлять ещё и список конкретных уязвимостей. Например, для этой угрозы, уязвимости могут быть такими: отсутствие регламента постановки помещения под охрану и, собственно, отсутствие крышки на системном блоке. Каждая из этих уязвимостей должна закрываться отдельно.
Для оценки рисков, вызванных наличием актуальных угроз, можно воспользоваться методикой оценки рисков от Digital Security. Формулы достаточно не сложные, обоснование тоже вроде как присутствует. О других методиках оценки рисков, нам никто не рассказывал.
По сути, подзаконные акты не требуют и не описывают процедуру оценки рисков, но оценив риски, можно закрывать угрозы не в произвольном порядке, а в порядке уменьшения риска, что достаточно логично.
Составив список актуальных угроз, можно провести классификацию ИСПДн по приказу трёх (который до сих пор никто не отменял) и установить уровни защищённости по постановлению 1119. С классификацией по приказу трёх я не хочу даже связываться, для специальных систем она делается на основании "экспертной оценки" (эксперт считает, что исходя из обрабатываемых ПДн и актуальных угроз, субъекту может быть нанесён значительный/незначительный вред и определяет класс ИСПДн), а вот уровень защищённости, по модели угроз, определяется хорошо. Во-первых, определяется тип актуальных угроз:
1-й, если актуальны угрозы НДВ в системном ПО;
2-й, если актуальны угрозы НДВ в прикладном ПО и неактуальны в системном ПО;
3-й, если угрозы НДВ не актуальны.
Во-вторых, определяется какие ПДн и в каком количестве обрабатываются (специальные, биометрические, иные, общедоступные) и на основании этих двух параметров определяется требуемый уровень защищённости.
Проблема здесь может крыться в том, что не все сертификаты ФСТЭК гарантируют отсутствие НДВ в ПО, на это следует обратить внимание.
В принципе, если ОС сертифицирована и угрозы 1-го типа неактуальны, то ИСПДн завода (с учётом того, что мы обрабатываем иные ПДн менее чем 100 000 человек) нужно будет обеспечить уровень защищённости 3, что вполне приемлимо.
Перечень применяемых мер, для обеспечения требуемого уровня защищённости, будет утверждён ФСТЭКом позднее. В декабре выходил проект их приказа, достаточно сильно раскритикованный в сети.
Далее, после определения уровня защищённости, нужно будет составить ТЗ на создание системы защиты ИСПДн. Желательно по ГОСТу 34.602. Вообще же, для оформления документов, желательно пользоваться ГОСТом 6.30. В этом случае, вряд ли у проверяющих будут претензии как минимум к оформлению.
Контроль доступа осуществляется на основе мандатного или дискреционного механизмов. Дискреционный доступ реализован и в операционной системе (каждому конкретному файлу "назначаются" пользователи, которые могут читать/писать/изменять файл) и не особо интересен. С мандатным интереснее. Во-первых, выделяются категории файлов, например - ПДн, коммерческая тайна и общедоступные данные. Во-вторых, каждому файлу назначается выбранная категория (поддерживается механизм наследования, т.е. можно на папку повешать "гриф" ПДн и все файлы, созданные в ней, или перемещённые туда, будут обладать этим грифом). В-третьих, для каждого пользователя определяется "наиболее серьёзный" гриф, который должен быть ему доступен и имеет ли этот пользователь возможность самостоятельного назначения грифов для файлов. Т.е., если пользователю, например, доступен гриф ПДн, то он сможет видеть все общедоступные файлы и файлы с грифом "ПДн", "коммерческая тайна" будет ему недоступна, а пользователь с правами доступа к коммерческой тайне, будет иметь возможность доступа к данным с любым грифом.
Проблемных мест, к сожалению, хватает. Во-первых, имеется возможность назначения всего трёх видов грифов, один из которых должен быть общедоступным. Это достаточно крупное разделение. Во-вторых, назначение доступных грифов пользователям - оно производится для каждого пользователя, нельзя назначить доступность грифа группе пользователей.
Контроль устройств. С ним всё относительно просто. Выбираются устройства и назначаются разрешения для конкретных пользователей. Удобно тем, что можно каждому пользователю выдать по флэшке и разрешить компьютере втыкать этому пользователю именно эту флэшку, а все остальные накопители запретить. В плане учёта материальных носителей ПДн - очень удобно. Есть возможность назначать права вообще на всё - вплоть до ядер процессора - применимость не совсем понятна, но есть и ладно.
Контроль целостности. К сожалению, сегодня мы с ним разобраться не успели. Смогли выбрать каталог для контроля целостности, создать там пару файлов и задать эталонные значения. Что должно происходить дальше - непонятно - то ли SecretNet должен запретить их изменение, то ли не должен. Ответ получить не смогли. Единственное, что контроль целостности ОС тормозит так сильно, что загрузка ОС вместо привычных 3-4 минут тянулась минут 10. Если на заводе загрузка будет идти столько же - пользователи нас казнят.
Плюс, нам не показывали, но сказали, что есть "центральная административная" консоль, через которую SecretNet можно настраивать в сети удалённо, со своего рабочего места. На курсах в ОмГУ говорили, что при таком варианте все журналы сообщений будут по сети сливаться на центральную машину и генерировать приличный траффик, тут же говорят, что журналы будут храниться локально и их просто можно просматривать с "центральной" машины.
После SecretNet'a некоторое время потратили на модель угроз. Ничего нового не было, всё есть в базовой модели угроз ФСТЭК и их же методических рекомендациях по выявлению актуальных угроз. Единственное, что при определении уровня исходной защищённости ("УИЗ"), можно сыграть на нечёткости формулировок и снизить этот уровень (например под одноточечным доступом в сеть общего пользования можно понимать как отдельный компьютер, "физически подключенный" к интернету, так и шлюз, через который выходит в интернет сотня пользователей).
Кроме того, для составления модели угроз можно воспользоваться программным продуктом WingDoc, он стоит порядка 15 тыр, гуглится легко. Отвечая на вопросы программы, формируется модель угроз и какие-то сопутствующие документы.
До составления модели угроз самостоятельно я не доходил, так что для меня стало открытием, что для актуальных угроз (например, хищение hdd из системного блока без боковой крышки), нужно составлять ещё и список конкретных уязвимостей. Например, для этой угрозы, уязвимости могут быть такими: отсутствие регламента постановки помещения под охрану и, собственно, отсутствие крышки на системном блоке. Каждая из этих уязвимостей должна закрываться отдельно.
Для оценки рисков, вызванных наличием актуальных угроз, можно воспользоваться методикой оценки рисков от Digital Security. Формулы достаточно не сложные, обоснование тоже вроде как присутствует. О других методиках оценки рисков, нам никто не рассказывал.
По сути, подзаконные акты не требуют и не описывают процедуру оценки рисков, но оценив риски, можно закрывать угрозы не в произвольном порядке, а в порядке уменьшения риска, что достаточно логично.
Составив список актуальных угроз, можно провести классификацию ИСПДн по приказу трёх (который до сих пор никто не отменял) и установить уровни защищённости по постановлению 1119. С классификацией по приказу трёх я не хочу даже связываться, для специальных систем она делается на основании "экспертной оценки" (эксперт считает, что исходя из обрабатываемых ПДн и актуальных угроз, субъекту может быть нанесён значительный/незначительный вред и определяет класс ИСПДн), а вот уровень защищённости, по модели угроз, определяется хорошо. Во-первых, определяется тип актуальных угроз:
1-й, если актуальны угрозы НДВ в системном ПО;
2-й, если актуальны угрозы НДВ в прикладном ПО и неактуальны в системном ПО;
3-й, если угрозы НДВ не актуальны.
Во-вторых, определяется какие ПДн и в каком количестве обрабатываются (специальные, биометрические, иные, общедоступные) и на основании этих двух параметров определяется требуемый уровень защищённости.
Проблема здесь может крыться в том, что не все сертификаты ФСТЭК гарантируют отсутствие НДВ в ПО, на это следует обратить внимание.
В принципе, если ОС сертифицирована и угрозы 1-го типа неактуальны, то ИСПДн завода (с учётом того, что мы обрабатываем иные ПДн менее чем 100 000 человек) нужно будет обеспечить уровень защищённости 3, что вполне приемлимо.
Перечень применяемых мер, для обеспечения требуемого уровня защищённости, будет утверждён ФСТЭКом позднее. В декабре выходил проект их приказа, достаточно сильно раскритикованный в сети.
Далее, после определения уровня защищённости, нужно будет составить ТЗ на создание системы защиты ИСПДн. Желательно по ГОСТу 34.602. Вообще же, для оформления документов, желательно пользоваться ГОСТом 6.30. В этом случае, вряд ли у проверяющих будут претензии как минимум к оформлению.
вторник, 12 февраля 2013 г.
День второй
Второй день на курсах был более насышенным.
Сначала мы быстро посмотрели на возможности Microsoft NAP, о котором я ранее даже не слышал. Правда не совсем понятна область применения. Возможно, при рассмотрении модели угроз, ясность появится.
Максим (наш лектор) рассказывал о технических каналах утечки. Рассказал и забавную историю о том, что при поиске "закладок" ("жучков"), при обнаружении такой закладки, прежде чем сообщать об этом заказчику, нужно направить запрос в ФСБ - узнать не они ли её установили.
Большую часть дня мы потратили на рассмотрение ОРД. Он обратил внимание на то, что когда приходит проверка, проверяющие могут не требовать какие-то конкретные документы для предоставления, а просить информацию в виде: "А каким образом вы закрываете требование 152 ФЗ, ст.19, п2., пп. 8 (например)". Как-то раньше о таком подходе я не задумывался, в основном искал именно список документов, которые требуют проверяющие. Надо будет взять 152 ФЗ, все подзаконные акты и пройтись по ним, составить свой список и сравнить с тем, который он нам дал.
Всего в списке Максима 31 документ, каждый мы быстро рассмотрели, хотя там всё понятно и из названия (типа "Политика безопасности", "Список лиц, допущенных к обработке ПДн" и т.д.).
Кроме того, он даёт такой список работ (в общем виде):
1. Выделение процессов обработки ПДн.
2. Выделение ИСПДн в различные подсистемы.
3. Классификация ИСПДн.
4. ТЗ на СЗПДн.
В принципе, примерно такой же план, давали и в ОмГУ. Первый пункт, этого плана, в свою очередь, делится на следующие шаги:
1. Назначение ответственного и комиссии.
2. Изучение внутренней и внешней ОРД - т.е. всех документов циркулирующих на предприятии.
3. Интервьюирование должностных лиц - определяем кто и что конкретно делает, выделяем цели обработки ПДн.
4. Идентификация точек входа и выхода информации, пути её перемещения на предприятии.
5. Изучение содержимого входящих и исходящих потоков информации - на этом этапе можно попытаться найти лишнюю информацию.
6. Выявление информации обрабатывающейся без использования средств автоматизации и с их использованием.
7. Анализ и уточнение оснований обработки, установка условий начала и прекращения обработки ПДн, определение категорий, обрабатываемых ПДн.
8. Определение структурных подразделений и должностных лиц, использующих ПДн в своей работе.
9. Составление и утверждение перечня ПДн, с учётом целей, оснований и сроков обработки.
В итоге, на выходе будет: перечень ПДн; список лиц, допущенных к обработке ПДн; описание процессов обработки ПДн.
Для описания самих процессов, по словам Максима, удобно использовать нотацию IDEF0, а для описания логики IDEF3. Честно говоря, с трудом представляю себе размер такой схемы для нашего предприятия, но, возможно, для небольших предприятий такой подход подойдёт.
Что будет дальше - будем посмотреть.
Сначала мы быстро посмотрели на возможности Microsoft NAP, о котором я ранее даже не слышал. Правда не совсем понятна область применения. Возможно, при рассмотрении модели угроз, ясность появится.
Максим (наш лектор) рассказывал о технических каналах утечки. Рассказал и забавную историю о том, что при поиске "закладок" ("жучков"), при обнаружении такой закладки, прежде чем сообщать об этом заказчику, нужно направить запрос в ФСБ - узнать не они ли её установили.
Большую часть дня мы потратили на рассмотрение ОРД. Он обратил внимание на то, что когда приходит проверка, проверяющие могут не требовать какие-то конкретные документы для предоставления, а просить информацию в виде: "А каким образом вы закрываете требование 152 ФЗ, ст.19, п2., пп. 8 (например)". Как-то раньше о таком подходе я не задумывался, в основном искал именно список документов, которые требуют проверяющие. Надо будет взять 152 ФЗ, все подзаконные акты и пройтись по ним, составить свой список и сравнить с тем, который он нам дал.
Всего в списке Максима 31 документ, каждый мы быстро рассмотрели, хотя там всё понятно и из названия (типа "Политика безопасности", "Список лиц, допущенных к обработке ПДн" и т.д.).
Кроме того, он даёт такой список работ (в общем виде):
1. Выделение процессов обработки ПДн.
2. Выделение ИСПДн в различные подсистемы.
3. Классификация ИСПДн.
4. ТЗ на СЗПДн.
В принципе, примерно такой же план, давали и в ОмГУ. Первый пункт, этого плана, в свою очередь, делится на следующие шаги:
1. Назначение ответственного и комиссии.
2. Изучение внутренней и внешней ОРД - т.е. всех документов циркулирующих на предприятии.
3. Интервьюирование должностных лиц - определяем кто и что конкретно делает, выделяем цели обработки ПДн.
4. Идентификация точек входа и выхода информации, пути её перемещения на предприятии.
5. Изучение содержимого входящих и исходящих потоков информации - на этом этапе можно попытаться найти лишнюю информацию.
6. Выявление информации обрабатывающейся без использования средств автоматизации и с их использованием.
7. Анализ и уточнение оснований обработки, установка условий начала и прекращения обработки ПДн, определение категорий, обрабатываемых ПДн.
8. Определение структурных подразделений и должностных лиц, использующих ПДн в своей работе.
9. Составление и утверждение перечня ПДн, с учётом целей, оснований и сроков обработки.
В итоге, на выходе будет: перечень ПДн; список лиц, допущенных к обработке ПДн; описание процессов обработки ПДн.
Для описания самих процессов, по словам Максима, удобно использовать нотацию IDEF0, а для описания логики IDEF3. Честно говоря, с трудом представляю себе размер такой схемы для нашего предприятия, но, возможно, для небольших предприятий такой подход подойдёт.
Что будет дальше - будем посмотреть.
понедельник, 11 февраля 2013 г.
День первый
Итак, завершился первый день курсов по обеспечению безопасности персональных данных от софтлайна.
Понравилось, что в отличии от курсов в ОмГУ, на которых я был в 2011-м году, всё происходит намного быстрее и весь курс, в целом, имеет более практическую направленость. Сегодня, за 5 часов, мы бегло прошлись по самому 152 ФЗ и новому постановлению правительства 1119 от 01.11.2012. И это ещё одно отличие от ОмГУ - там мы в декабре 2011-го изучали "старую" версию 152 ФЗ, без "свежих" на тот момент поправок от 25.07.2011. Так же, мы бегло рассмотрели возможности SecretNet и VipNet. В принципе, об использовании SecretNet'а можно было бы подумать, если бы все файлы на шарах были рассортированы по категориям.
Особенно же интересны сегодня были два момента. Первый - это является ли фотогрфия в пропуске биометрическими ПДн или нет. В интернете единого мнения нет. Одни говорят, что по ГОСТу к биометрии можно отнести только один тип фотографий - те, которые используются в загранпаспорте и им подобные - т.е., хранящих, помимо изображения, ещё кучу дополнительных данны (набор контрольных точек, пол и т.д.). Другие говорят, что если эта фотография используется для "установления личности субъекта персональных данных", то она, согласно 152ФЗ (и ПП 1119) является биометрией (ст. 5 ПП 1119). Наш лектор сторонник первой точки зрения. Он говорит, что вообще определение "установление личности" можно найти только в уголовном кодексе и оно возможно только по "настоящей" биометрической фотографии, при наличии специального оборудования. То же, чем занимается охранник на КПП - это "удостоверение тождественности
личности гражданина с лицом,
изображенным на фотографии", что отличается от "установления личности" как идентификация от аутентификации. Т.е. он признаёт, что человек на фото совпадает с человеком, предъявляющим пропуск, но не гарантирует, что в пропуске всё верно (т.е. он не знает, правильно ли там указана фамилия, например). В общем, об этом стоит подумать.
Второй момент - это озвученная лектором позиция ФСТЭК о выходе новых подзаконных актов. "Считайте все выходящие нормативные документы дополнением к уже вышедшим ранее, если явно не указанно обратное". Т.е., в ПП 1119 явно указано, что ПП 781 утратило силу, соответственно, само ПП 781 принимать во внимание не требуется, а вот, например, приказ 58 (дочерний от ПП 781) остаётся действительным до тех пор, пока его явно не опишут как "утративший силу". Позиция неприятная для меня, как представителя оператора, но хотя бы понятная. В принципе, пока в плане проверок нас нет, будем продолжать ждать выхода новых документов.
Ну и ещё один забавный момент. Лектор при мне позвонил какому-то знакомому, работающему у Челябинского лицензиата по ТЗКИ, и спросил сколько будет стоить разработать комплект документации по 152 ФЗ для предприятя, предположительно К2-К3 и получил ответ: "20-25 тыр". Нам же, местные, предлагают разработать комплект документов за 500 тыр (цифра из реального коммерческого предложения). Вот такие дела. Будем ждать следующего дня.
четверг, 7 февраля 2013 г.
Мобильный blogger
Установил себе мобильное гугловское приложение Blogger. Будем посмотреть, возможно начну писать чаще.
С понедельника начинаются курсы по безопасности персональных данных от софтлайна, так что можно сказать, что приложение я себе установил очень кстати.
Пока не знаю насколькоудобно будет писать большие тексты на телефоне, но пока всё устраивает.
Как работает DTA в SQL Server
В SQL Server, начиная с 2005-го, присутствует такой компонент как Database Tuning Advisor. Он может проанализировать рабочую нагрузку и предоставить свои рекомендации по созданию/удалению индексов для повышения производительности.
Не сказать, чтобы мне прям было очень интересно как он работает. Теоретически, глядя на условия соединения таблиц, выбираемые поля, сортировки и прочее - можно предоставить рекомендации по создаваемым индексам. Мой диплом, например, назывался "Инструментарий для оптимизации запросов в среде 1с 8.1", который этим и занимался. Смотрел какие индексы есть, какие поля остаются неиндексированными и, основываясь на этих данных, давал свои рекомендации. Надо признать, что спустя 4 года я понимаю какую ересь он предлагал, но сам подход, в принципе, можно, наверное считать приемлемым.
Ну так вот, возвращаясь к DTA. Я думал, что примерно такую же работу он и проводит. Но, оказалось, что это не совсем так. Точнее, возможно, именно этим он и занимается, но не в том виде, как я себе это представлял.
Итак, у SQL Server есть несколько интересных недокументированных возможностей.
1) При создании индекса есть возможность указать WITH STATISTICS_ONLY.
Это заставляет SQL Server создать гипотетический (hypothetical) индекс. Т.е. фактически создаётся такой индекс, который нельзя использовать в обычных запросах (и который никак не учитывается оптимизатором), но который, как бы существует. Ещё есть возможность указания WITH STATISTICS_ONLY = -1 - тогда индекс будет гипотетическим, но, вот статистика, созданная по этому индексу, будет вполне себе реальной.
2) DBCC AUTOPILOT и SET AUTOPILOT.
Как я уже говорил - гипотетический индекс не может использоваться при выполнении запросов. Но, с помощью DBCC AUTOPILOT мы можем заставить оптимизатор создать такой план запроса, какой он создал бы при наличии этого индекса в "обычном", не гипотетическом, виде.
Итак, чтобы использовать DBCC AUTOPILOT, выполним:
DBCC TRACEON (2588)
DBCC HELP('AUTOPILOT')
и увидим описание:
DBCC AUTOPILOT (typeid [, dbid [, {maxQueryCost | tabid [, indid [, pages [, flag [, rowcounts]]]]} ]])
Итак, чтобы выполнить запрос с учётом гипотетического индекса, в режиме "автопилота", нужно сделать следующее:
1. Создать индекс WITH STATISTICS_ONLY.
2. Узнать идентификатор БД: select db_id()
3. Узнать id таблицы и id индекса, например из sysindexes
4. Вместо остальных значений можно использовать нули, а можно попробовать поиграться и проанализировать результаты.
5. Выполнить SET AUTOPILOT ON
6. Выполнить DBCC AUTOPILOT.
7. Выполнить запрос и посмотреть его план выполнения. Если гипотетический индекс будет являться оптимальным для этого запроса, он будет использоваться.
8. Выполнить SET AUTOPILOT OFF
В общем, штука крутая, но с ней надо быть осторожным. Недокументированные возможности всегда используются на свой страх и риск (и я никому не советовал бы использовать их на продакшене).
О DBCC AUTOPILOT я узнал отсюда (мой перевод на хабре). Примерно тоже самое, от того же автора, но с более удобным вариантом использования есть здесь. О гипотетических индексах можно почитать здесь.
Не сказать, чтобы мне прям было очень интересно как он работает. Теоретически, глядя на условия соединения таблиц, выбираемые поля, сортировки и прочее - можно предоставить рекомендации по создаваемым индексам. Мой диплом, например, назывался "Инструментарий для оптимизации запросов в среде 1с 8.1", который этим и занимался. Смотрел какие индексы есть, какие поля остаются неиндексированными и, основываясь на этих данных, давал свои рекомендации. Надо признать, что спустя 4 года я понимаю какую ересь он предлагал, но сам подход, в принципе, можно, наверное считать приемлемым.
Ну так вот, возвращаясь к DTA. Я думал, что примерно такую же работу он и проводит. Но, оказалось, что это не совсем так. Точнее, возможно, именно этим он и занимается, но не в том виде, как я себе это представлял.
Итак, у SQL Server есть несколько интересных недокументированных возможностей.
1) При создании индекса есть возможность указать WITH STATISTICS_ONLY.
Это заставляет SQL Server создать гипотетический (hypothetical) индекс. Т.е. фактически создаётся такой индекс, который нельзя использовать в обычных запросах (и который никак не учитывается оптимизатором), но который, как бы существует. Ещё есть возможность указания WITH STATISTICS_ONLY = -1 - тогда индекс будет гипотетическим, но, вот статистика, созданная по этому индексу, будет вполне себе реальной.
2) DBCC AUTOPILOT и SET AUTOPILOT.
Как я уже говорил - гипотетический индекс не может использоваться при выполнении запросов. Но, с помощью DBCC AUTOPILOT мы можем заставить оптимизатор создать такой план запроса, какой он создал бы при наличии этого индекса в "обычном", не гипотетическом, виде.
Итак, чтобы использовать DBCC AUTOPILOT, выполним:
DBCC TRACEON (2588)
DBCC HELP('AUTOPILOT')
и увидим описание:
DBCC AUTOPILOT (typeid [, dbid [, {maxQueryCost | tabid [, indid [, pages [, flag [, rowcounts]]]]} ]])
Итак, чтобы выполнить запрос с учётом гипотетического индекса, в режиме "автопилота", нужно сделать следующее:
1. Создать индекс WITH STATISTICS_ONLY.
2. Узнать идентификатор БД: select db_id()
3. Узнать id таблицы и id индекса, например из sysindexes
4. Вместо остальных значений можно использовать нули, а можно попробовать поиграться и проанализировать результаты.
5. Выполнить SET AUTOPILOT ON
6. Выполнить DBCC AUTOPILOT.
7. Выполнить запрос и посмотреть его план выполнения. Если гипотетический индекс будет являться оптимальным для этого запроса, он будет использоваться.
8. Выполнить SET AUTOPILOT OFF
В общем, штука крутая, но с ней надо быть осторожным. Недокументированные возможности всегда используются на свой страх и риск (и я никому не советовал бы использовать их на продакшене).
О DBCC AUTOPILOT я узнал отсюда (мой перевод на хабре). Примерно тоже самое, от того же автора, но с более удобным вариантом использования есть здесь. О гипотетических индексах можно почитать здесь.
Подписаться на:
Сообщения (Atom)